
Recently I visited the microservices conference Microxchg. Here is a wrap up about State of the Art concepts in modern microservices architectures. Following all the principles and techniques described here brings you right to Microservices Nirvana.
Be warned this blogpost is more like a short and dense list. It may contain a whole lot of buzzwords. 🙂
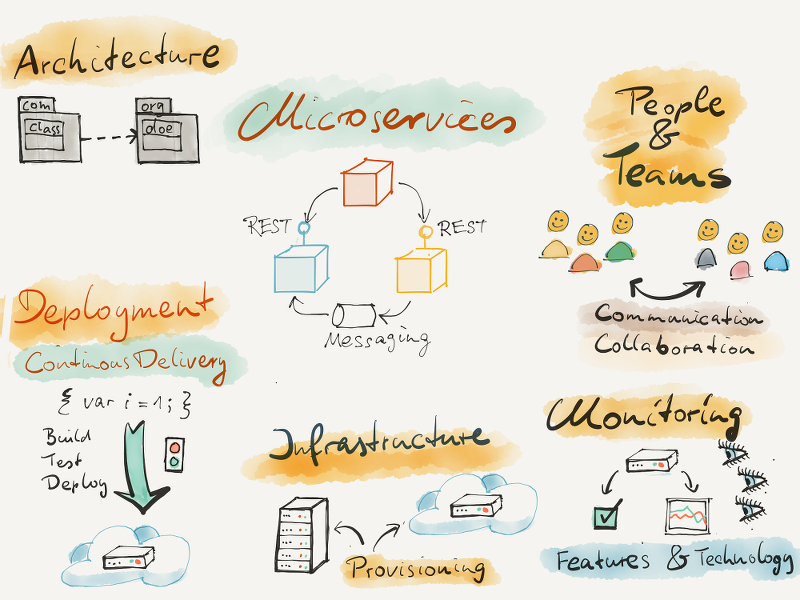
People and Teams
- Each microservice is developed and cared for by one team.
- Each team has several microservices they build and run.
- Teams build test deploy and monitor the services themselves.
- The team has a big impact and sometimes the only saying in which technologies and frameworks they use.
- Teams working with a microservices architecture can go faster once they have mastered the technical challenges.
- Microservices make it a lot easier to try out new technologies wich makes developers happy.
- Microservices architectures work best when there is organisational alignment. See Conways Law.
Architecture
- Microservices are only allowed to share libraries from open source projects.
- Each microservice needs to be documented. Its API should be made easily accessable.
- Microservices are almost always run in many instances grouped in clusters.
- Orchestration of microservices is supported by tools like Docker Compose.
- Patterns are used to describe solutions to particular problems in the microservice architecture style. “www.microservices.io”
- Scale Free Architecture is an architecture that is able scale to any size without any need to adjust it.
- Serverless architectures like AWS Lambda can be the next step after microservices.
- Reactive fault tolerant microservices architectures using message busses such as Akka could be a next step to architectures with thousands of services.
- Each microservice complies to the twelve factor app concept.
- A slightly different concept to microservices is the Self Contained System architecture.
Microservices and Monoliths
- There is not a clear winner between starting with a monolith or starting with a microservices architecture.
- Microservices may pose more technical challenges in the beginning.
- Monoliths may be better to start with if the problem domain is not wholly understood.
- Microservices introduce complexities and new problems. But each those complexities can be dealt with individually whereas there are problems in monolithic apps that are hard to fix at all.
- Microservices reap the most benefits when you have several teams and you want them to go fast.
Mindshift from Monolith to Microservices
- Code duplication is not a bad thing by itself. DRY needs to be balanced with other principles like low coupling.
- Not all developers may like the job enrichment character of having to do development, test, deployment, monitoring, UX, DevOps.
- It is OK to throw away services or rewrite them. Microservices enable this.
- Maintaining monolithic applications may take more effort in the long run than the infrastructure overhead of microservices in the beginning.
Service Communication
- Microservices interact most of the time using REST or messaging. Seldom they use webservices.
- Microservices don’t share a database.
- Microservices only talk to each other via published APIs.
- APIs should be backward compatible in order to enable change.
- If you follow Postels Law you will be fine with changing your system.
DDD
- Domain Driven Design is a central concept to find the right structure and boundary of services.
- An individual aspect or part of the domain usually results in a microservice holding and managing that aspect.
- When constructing the bounded contexts it is important to distinguish between entity objects and value objects. Aggregations are a great way to structure entities and its value objects.
Operational aspects
- DevOps and Microservices go hand in hand.
- Each service is monitored and metrics are gathered.
- The state of the whole system and its services is visualized and made easily available to the teams.
- Each team is responsible for the operation of its services.
- More and more microservices based applications run in the cloud such as AWS and Azure.
- Systems and stages are described as “Infrastructure as Code”. This enables infrastructure to be immutable. Infrastructure and services should be managed more like cattle than like pets.
- Dealing with failure is an integral part of the application infrastructure.
Concepts like Green Blue Deployment, Circuit Breakers, Chaos Monkey and Failover procedures are used to migitate and even provoke failures. - Microservices communication is measured and monitored e.g. with zipkin.
- The logging data can be analyzed using monte carlo simulation. A tool exists to visualize the distributions (see www.getguestimate.com)
- Management of passwords and credentials is done using Hashicorp Vault www.vaultproject.io
- Your logging format should be seen as an API between application and monitoring systems.
- The ELK Stack is used often as a log management tool. There are also great commercial products for Log Management like Splunk or Sumo Logic.
Deployment
- Each service is build and deployed using a Continous Deployment pipeline.
- Assure the integrity of the whole system with contract tests that are run in the continous deployment pipeline. The interopability with other consumers and producers is tested with the new version of the service.
- Services are deployed as BLOBs that contain all the dependencies and configuration.
- Docker is a great packaging format.
- There are more and more tools and plattforms that help managing the deployment workflow like Spinnaker.
- Service Discovery is an integral part of delivery. Tools like Consul support it.
- Docker is now a safe technological bet. There is a huge and growing community of services and tools to build on.
- Spinnaker is a tool that helps manage the deployment process. Those deployment processes should also be described in code.
- DNS is a simple and powerful tool to use for service discovery.
Final Thoughts and Conclusions
Some people dislike the term microservice because it is misleading. But the concepts and development in this space are big push in the right direction when developing large web based systems.
You are probably not in the infrastructure business. Don’t try to build your own AWS.
Logging and monitoring with ELK, Kibana, Grafana and so on is cool and fun – but don’t forget to create business value.
Heterogeneity in your programming languages and tools gives you options and flexibility. But there is a risk of overstretching and becoming unable to maintain your systems.
I think microservices concepts are still evolving and maturing. New concepts like serverless architectures are the next steps in the evolution.
In the future there will be no “either or” between monoliths and microservices. Both and a combination are valid architecture concepts.
There is still a speed bump for most organisations that switch to microservices. There are a lot of technologies and concepts to learn. Senior developers are needed to manage this transition.

